The Kubernetes NVIDIA GPU Operator — Overview and Tutorial
The backbone of AI
High-Performance Computing (HPC) has become the backbone of innovation in machine learning and AI, but it comes with its own set of challenges. At scale, the cost and performance of an ML project are typically optimized by leveraging Kubernetes alongside hardware-accelerated nodes.
GPUs are the essential substance for accelerating these ML workloads, however, managing them effectively is far from simple. One major issue is GPU utilization in productive scenarios. Typically the GPUs are not fully utilized during model inference, leaving a lot of spare resources unused. In a cloud environment, this results in higher operational cost and extended processing times, creating significant inefficiencies in both business and technical aspect.
Thankfully, virtualization technology enables GPUs to be partitioned into smaller, more efficiently used resource chunks which solves the aforementioned issue.
There are different ways to run concurrent workloads on a GPU. In this article we are going to concentrate on how to achieve this using Kubernetes, the Nvidia GPU operator and a time slicing approach. But before we get to the hands on, let’s take a look at the Nvidia Operator and which GPU partitioning options it provides out of the box.
Concurrency Mechanisms
Depending on the GPU family architecture there are currently three technologies allowing GPU partitioning.
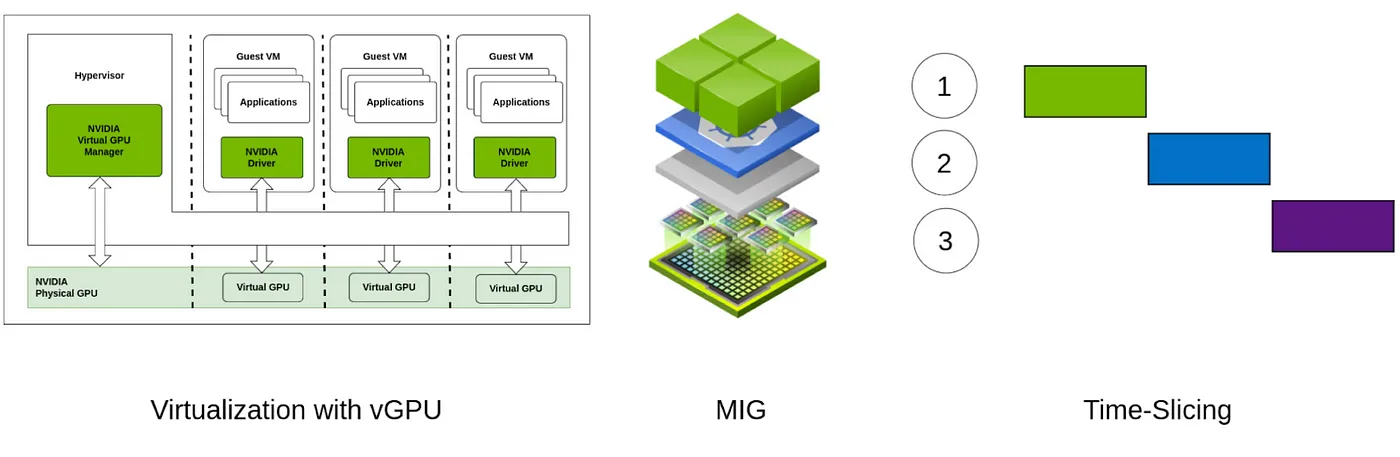
Time-Slicing
CUDA uses an asynchronous processing model allowing for multiple separate processes that use the GPU to run in parallel. This is achieved with a Round-robin scheduling approach. On the software level each CUDA process is isolated from the rest and given a time period in which it is allowed to be executed using the CUDA cores. This approach provides no memory isolation besides the isolation between the processes running on different CUDA contexts. This can lead to Out Of Memory (OOM) errors when a context tries to allocate more memory than what is currently free.
Virtual GPUs (vGPU)
The vGPU Virtualization technology allows a single physical GPU to be shared among multiple virtual machines (VMs). Each virtual GPU behaves like a separate GPU, allowing each VM to run its GPU workload isolated from the others. The virtualization is achieved on the software level.
Multi Instance GPU (MIG)
Newer GPUs support MIG technology that allows hardware native partitioning into as many as seven fully isolated instances, each with its own VRAM, cache, and compute cores.
All those partitioning approaches are available on Kubernetes using the Nvidia GPU Operator.
The NVIDIA GPU Operator
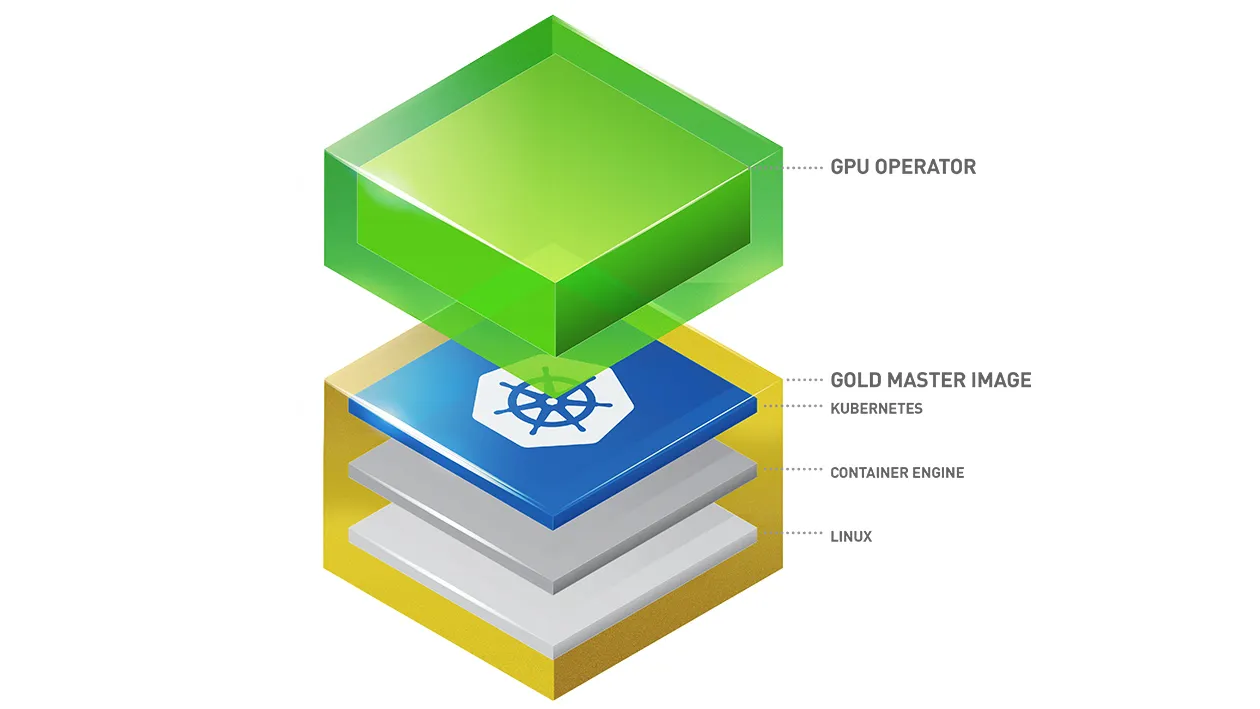
The GPU Operator is a Kubernetes add-on that simplifies the deployment and management of GPU resources in a cluster. It automates the installation of essential GPU software components such as drivers, container runtimes, monitoring tools, and workload scheduling extensions, ensuring optimal performance and compatibility.
Here is a list and brief description of the components:
-
GPU Operator: The main controller component that manages the deployment and lifecycle of GPU-related resources in the Kubernetes cluster. Deploys the necessary components such as the NVIDIA driver, device plugins, and GPU monitoring tools.
-
GPU Operator Validator: A component that validates the environment to ensure the proper setup of GPU resources and dependencies. Checks if the required GPU drivers and device plugins are correctly installed and functioning.
-
Driver: Installs the NVIDIA GPU drivers onto the nodes of the Kubernetes cluster.
-
Container Toolkit: Supplies the CUDA toolkit and other libraries that are needed for GPU-accelerated workloads.
-
Kubernetes Device Plugin: Ensures that Kubernetes can schedule workloads that require GPU resources. Ensures that workloads are aware of the available GPUs and can request them when needed.
-
DCGM Exporter: Monitors the status and health of NVIDIA GPUs in the cluster. Collects GPU metrics (e.g., GPU usage, temperature, memory utilization) and exposes them to monitoring systems such as Prometheus.
-
GPU Feature Discovery (GFD): Detects and exposes GPU-related features for use in workloads. Scans the nodes for available GPU features and capabilities (e.g., memory size, CUDA capability).
-
MIG Manager (Multi-Instance GPU): Allows GPUs to be hardware partitioned into smaller instances, each of which can be assigned to different workloads. Helps maximize the utilization of GPUs by enabling multiple workloads to share a single physical GPU.
-
Node-Feature-Discovery: Scans the nodes for available hardware features and assigns Kubernetes labels accordingly.
Installing the operator
In this hands on you are going to learn how to install the NVIDIA GPU Operator on a Kubernetes cluster. For the sake of this tutorial we are going to run it on minikube cluster that has GPU passthrough configured.
You can learn how to enable GPUs in minikube from the official documentation
Let’s start with installing the GPU Operator following the steps in the NVIDIA documentation:
1
2
3
4
5
6
7
8
# Add the nvidia helm repostiory
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
# Update the repostiories to get the latest changes
helm repo update
# Install the nvidia operator helm chart
helm install --wait --generate-name -n gpu-operator --create-namespace nvidia/gpu-operator
Wait until all pods in the gpu-operator namespace are ready. Afterwards if we check the minikube node labels we are going to find out that the feature discovery plugin has added a bunch of labels. More interesting here are the nvidia.com/gpu.count and nvidia.com/gpu.replicas. We can see that both of them have a value of 1 corresponding to the single RTX 3060 GPU on the minikube node.
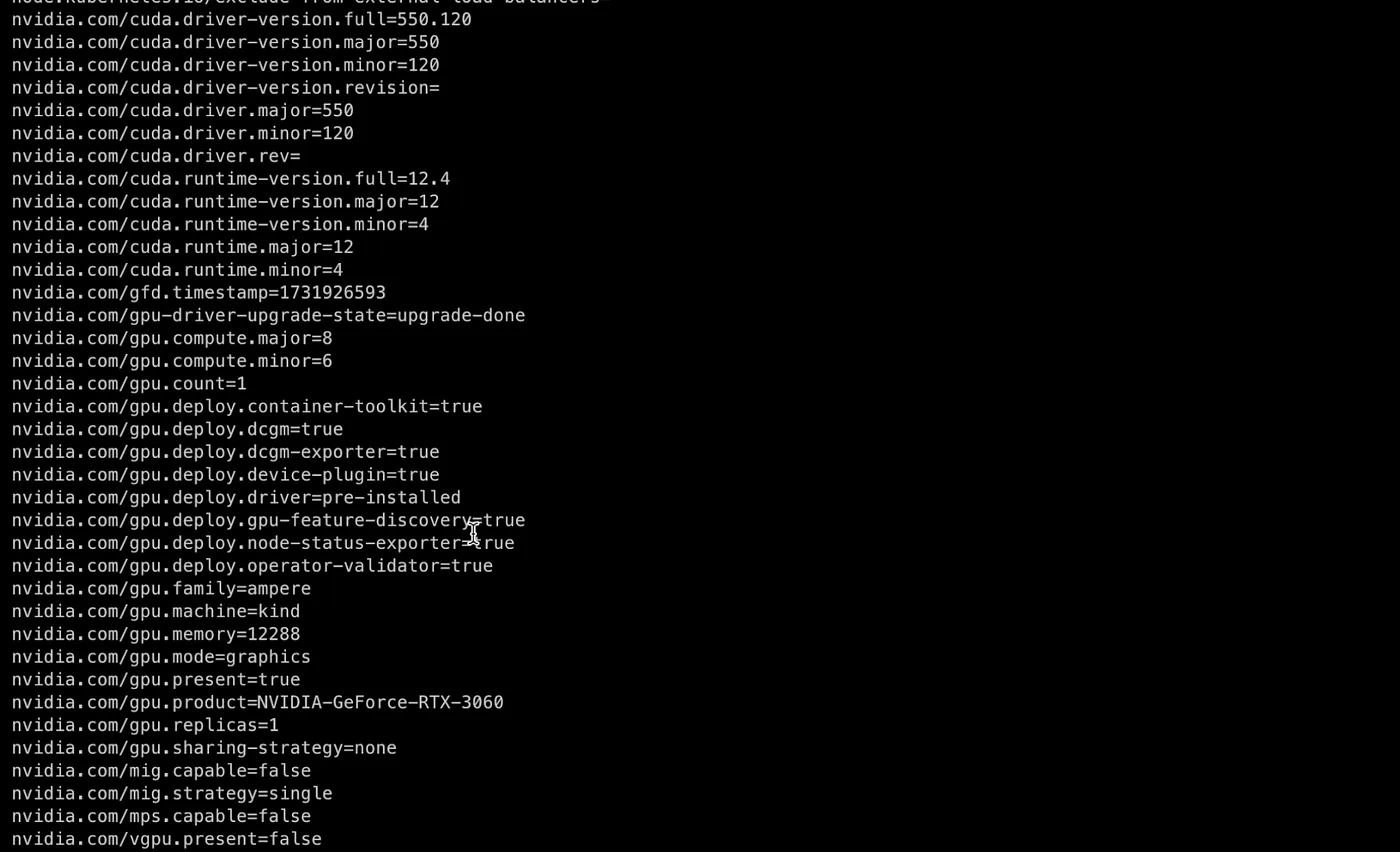
Now you should be able to request GPU resources when defining a Deployment. However, there is still one issue. There is a single GPU resource that can be requested by a single Pod. This results in the same behavior as of a system without the Kubernetes orchestrator leading to no utilization gains. There is something more that we should do.
Partitioning the GPU with a Time-Slicing Approach
The RTX 3060 is commercial device targeting mostly gaming use cases. It uses the Ampere architecture and does not support neither MIG nor vGPU technology. The only choice left here is to apply Time-Slicing which to our luck works on all CUDA architectures. Following the official NVIDIA Time-Slicing in Kubernetes documentation we can split the GPU into as much replicas as we want, which will be available as a nvidia.com/gpu.count resource on the cluster.
Let’s define a cluster wide Time-Slicing configuration creating 4 GPU replicas and save it in a time-slicing-config.yaml file.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
apiVersion: v1
kind: ConfigMap
metadata:
name: time-slicing-config-all
data:
any: |-
version: v1
flags:
migStrategy: none
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 4
Apply the created ConfigMap to create it as a resource on the cluster and set it as the default time-slicing configuration in the cluster policies:
1
2
3
4
5
kubectl create -n gpu-operator -f time-slicing-config.yaml
kubectl patch clusterpolicies.nvidia.com/cluster-policy \
-n gpu-operator --type merge \
-p '{"spec": {"devicePlugin": {"config": {"name": "time-slicing-config-all", "default": "any"}}}}'
Afterward, when the device plugin finds the new configuration, you should see that the minikube node has updated labels that correspond to the new setup:
- nvidia.com/gpu.count has still a value of 1 because we have a single GPU device
- nvidia.com/gpu.replicas has a value of 4 corresponding to the updated setup
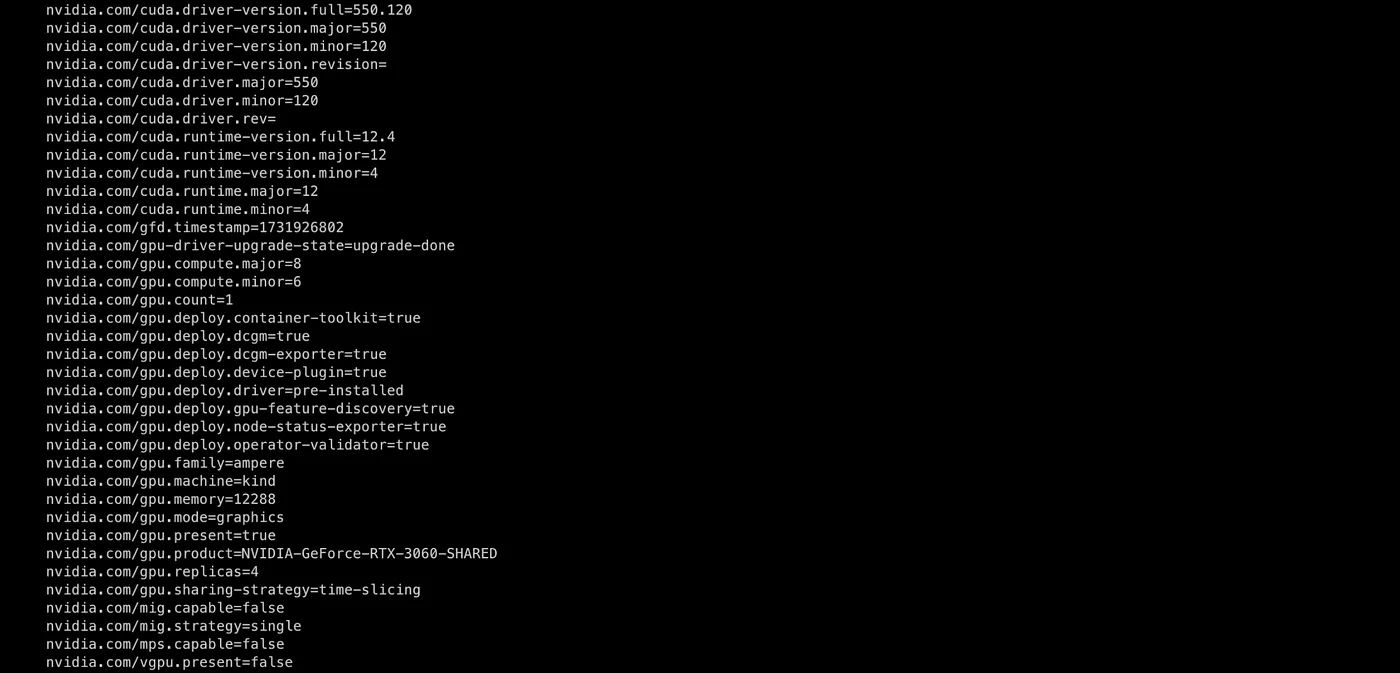
If we take a look at the node capacity we are going to see 4 gpu:
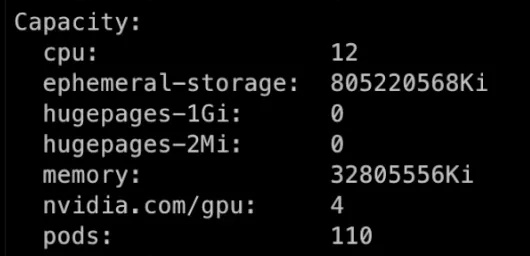
Effectively we split the GPU into 4 virtual replicas with 1/4 of the original memory. Here it is important to remember that the processes in the containers of the pods using the GPU resources are not aware of the GPU size. Instead, each process has access to the full GPU memory as there is no memory isolation. Here it is up to the developer to take care of the resource management and make sure no OOM are caused by oversubscribing.
Final words
This is how you can enable the NVIDIA GPU Operator that automates the configuration of GPU nodes in Kubernetes. What is left now is to define the GPU capacity that a Kubernetes resource request by adding the following field in the corresponding YAML:
1
2
3
4
5
6
.
.
.
resources:
limits:
nvidia.com/gpu: 1