How to add memory to a chat LLM model
Why is memory needed
Large Language Model (LLMs) exhibit remarkable capabilities as standalone solutions for various natural language processing tasks. Out of the box, LLMs are proficient at text summarization, text classification, language understanding, and simple cognitive tasks. However, LLMs are not completely perfect and as any other technical system, extending them with additional features makes them progressively more capable and clever.
As we saw in my previous post, adding context to LLM prompts with the help of the Retrieval Augmented Generation (RAG) approach can extend the knowledge of our model and improve the “hallucinations” disadvantage. However, if we aim at creating a human-like chatbot, RAG is not sufficient as it only mimics long-term memory. To implement short-term memory (i.e. conversational memory), we need a separate feature that will make our model keep context of the current conversation.

In this post we are going to see how to implement such conversational memory from scratch and also some standardized and extendable approaches to get this done. Get excited and let’s dive head first in the coding! :)
Needed tools
LangChain
LangChain, as mentioned previously, is the Swiss knife of your GenAI project. It comes with a lot of standardized components for AI projects and makes building custom AI solutions as easy as playing with Lego blocks. We use LangChain to implement the conversational memory of our chatbot, so let’s install it with:
pip install langchain
Language Model
At the core of our projects lies a large language model, acting as the semantic engine for our chat bot. In my previous tutorials I have already covered how to run Llama 2 on CPU and how to host it as an OpenAI compatible server.
In this tutorial we will need a model that is hosted on an OpenAI compatible server again. This was also covered already so make sure to checkout the prerequisite of my previous post to find out how to do it.
Bare Bones Approach
To start with, let’s see how we can implement a very crude and basic version of LLM memory. Afterwards we will achieve the same using the standardized components from LangChain.
Similar to the RAG approach, conversational memory has to be provided as context to our model. For time being LLMs provide a single way to for context injection and that is by using the model prompt.
Extending the model prompt
Let’s start with analyzing again the prompt template that chat version of Llama 2 uses:
1
2
3
4
prompt = f"""<s>[INST] <<SYS>>
{system_message}
<</SYS>>
{user_message} [/INST]"""
To clarify what what we see, we must understand the special tokens marked with <<>>.
- Using the
<<SYS>>and<</SYS>>tokens we instruct the act in a specific way (i.e. we define the model behavior). - Using the
<<INST>> and<</INST>>tokens we wrap the system behavior and instill it with the user prompt (i.e. user message).
This is probably nothing new. In this tutorial, we are also going to consider the <s> which comes in handy when we want our model to keep track of the conversational context (i.e. when we implement the conversational memory).
Thanks to the way the Llama 2 model has been trained, we can integrate the conversation into the prompt. To make this more clear, let’s consider the following situation:
- We have prompted our model
- We have saved the generated output in the variable
model_output - Our next prompt is saved in the variable
next_user_message.
Now we want to prompt our model and continue the conversation by keeping track of the initial prompt. To achieve this we can extend the prompt template in the following way:
1
2
3
4
prompt = f"""<s>[INST] <<SYS>>
{system_message}
<</SYS>>
{user_message} [/INST] {model_output} </s><s>[INST] {next_user_message}[/INST]"""
As you can see, we have wrapped the model input together with the generated output using the <s> and </s> tokens. Those tokens mark the beginning and end of a whole sequence. Additionally, you can see that we start the next sequence with an opening <s> token before we wrap the next user prompt with the <INST> tokens. Using this approach, we can extend the prompt with the conversational history. In this way the model will ratain the conversational context.
Prompting the model
Thankfully, the OpenAI compatible server together with the OpenAI client have this functionality handled under the hood. Prompting the model with an http request can be achieved like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
from langchain_openai import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage, AIMessage
chat = ChatOpenAI(model_name="llama-2-chat",
openai_api_base="http://localhost:8000/v1",
openai_api_key="sk-xxx",
max_tokens=2048,
temperature=0.7)
messages = [
SystemMessage(
content="<describe ai system behaviour here>"
),
HumanMessage(
content="<your model prompt here>"
),
AIMessage(
content="<here comes the first model output>"
),
HumanMessage(
content="<your second model prompt here>"
),
AIMessage(
content="<here comes the second model output>"
),
.
.
.
HumanMessage(
content="<your n-th model prompt here>"
),
]
output = chat.invoke(messages)
print(output.content)
Here, the messages list contains the conversation history and provides it as a context to the model for each next generation prompt.
Note: Yet simple, this approach has some limitation which will become apparent in the long run. Keeping track of the whole discussion history and using it as part of the prompt will increase the prompt size after each iteration. Eventually, the prompt will grow beyond the maximal token count and our model will not be able to handle it. There are more advanced memory solutions to solve this issue, which I will cover in future articles.
Before we proceed further, I suggest you start your OpenAI compatible server and play around with the code above to get a better understanding of the concept.
LangChain Memory
The LangChain framework provides a solution to the functionality that we implemented in the code above. In addition, the Memory feature comes as extendable and interchangeable modules with different functionality.
In this article we are going to check out the ConversationalBufferMemory which has the exact same behavior as what we have coded ourselves, but there are also other options such as ConversationSummaryMemory which keeps context of the discussion in the form of a summary and can solve the problem with of the growing prompt length.
ConversationalBufferMemory
To see how we can use this memory type, let’s look the following example where we create a financial advisor AI chatbot. We will start by creating a prompt template that will dynamically parse the generated messages:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
from langchain.prompts import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
MessagesPlaceholder,
)
from langchain.schema import SystemMessage
prompt = ChatPromptTemplate.from_messages(
[
SystemMessage(
content="You are a finantial advisor chatbot giving precise and concise answers on financial topics."
), # The persistent system prompt
MessagesPlaceholder(
variable_name="chat_history"
), # Where the memory will be stored.
HumanMessagePromptTemplate.from_template(
"{human_input}"
), # Where the human input will injected
]
)
We can now utilize the memory module and configure it to work with the created template:
1
2
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
Here we provide the key chat_history which will be used by the memory module to dump the conversation history.
Using the prompt and memory objects, we can now create our LLM chain and use it to provide context to our language model:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from langchain_openai import ChatOpenAI
from langchain.chains import LLMChain
llm = ChatOpenAI(model_name="llama-2-7b-chat",
openai_api_base="http://localhost:8000/v1",
openai_api_key="sk-xxx",
temperature="0.7",
max_tokens=2048)
chat_llm_chain = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory,
)
Note: The ChatOpenAI object in the code above is configured to talk to aself hosted Llama 2 chat model server. If you remove the
openai_api_baseand provide a properopenai_api_key, you can use the ChatOpenAI object with OpenAI models instead.
This is everything that we have to do to implement simple conversational memory for our LLM. The last step is to prompt the model using the LLM chain that we created.
We have configured the chain to work in verbose mode, so that we can see what is kept track of in the memory:
1
2
answer = chat_llm_chain.predict(human_input="How can I start investing?")
print(answer)
This prompt results in the following output:

If we prompt the model directly once again, we will see that the previous data is contained in the current prompt:
1
2
answer = chat_llm_chain.predict(human_input="Which are some good online brokers?")
print(answer)
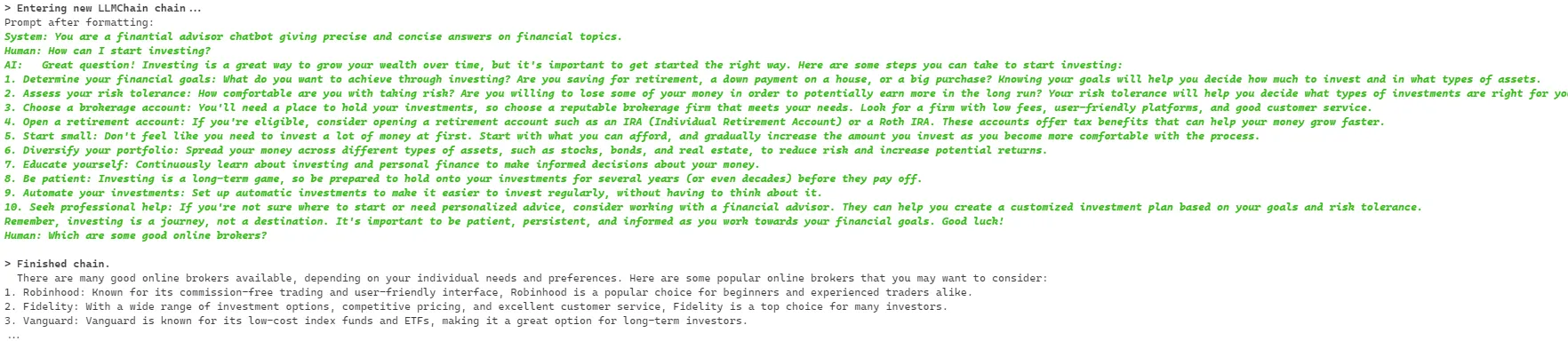
And that is it our self hosted LLM has a memory and can keep track of the conversation context.